FjQMN2IWAAEqJp0 jpeg
(191.75 KB, 1442x1572)
FjQK73fXkAE81Zk jpeg
(196.24 KB, 1440x1492)
FjQK4z8WAAAe1cq jpeg
(210 KB, 1446x1668)
>>/987/
Насчёт науки забыл маленькое, но важное:
https://arxiv.org/abs/2211.09862
> Here, we introduce Distilled DeepConsensus - a distilled transformer-encoder model for sequence correction, which improves upon the HMM-based methods with runtime constraints in mind. Distilled DeepConsensus is 1.3x faster and 1.5x smaller than its larger counterpart while improving the yield of high quality reads (Q30) over the HMM-based method by 1.69x (vs. 1.73x for larger model). With improved accuracy of genomic sequences, Distilled DeepConsensus improves downstream applications of genomic sequence analysis such as reducing variant calling errors by 39% (34% for larger model) and improving genome assembly quality by 3.8% (4.2% for larger model).
Одно банальное применение трансформеров к биоданным больше повышает качество/удешевляет секвенирование генома, чем 2-4 года традиционного R&D Illumina или BGI. Грубо говоря, можно делать покрытие X20 вместо X30. Это уже даст сотни миллионов экономии (консервативно) и приближение персонализованной медицины для среднего туловища. (Учитывая, как растёт наше понимание трансформеров, диффузии и других примитивов в основе современных моделей – я ожидаю ещё кратно лучших результатов).
Но конечно кому это нахуй нужно! Не практично, не достижение, давайте лучше поговорим про то, как скоро нейросети заменят обскурных дохлых классических композиторов, вот это мерило ума.
>>/1214/
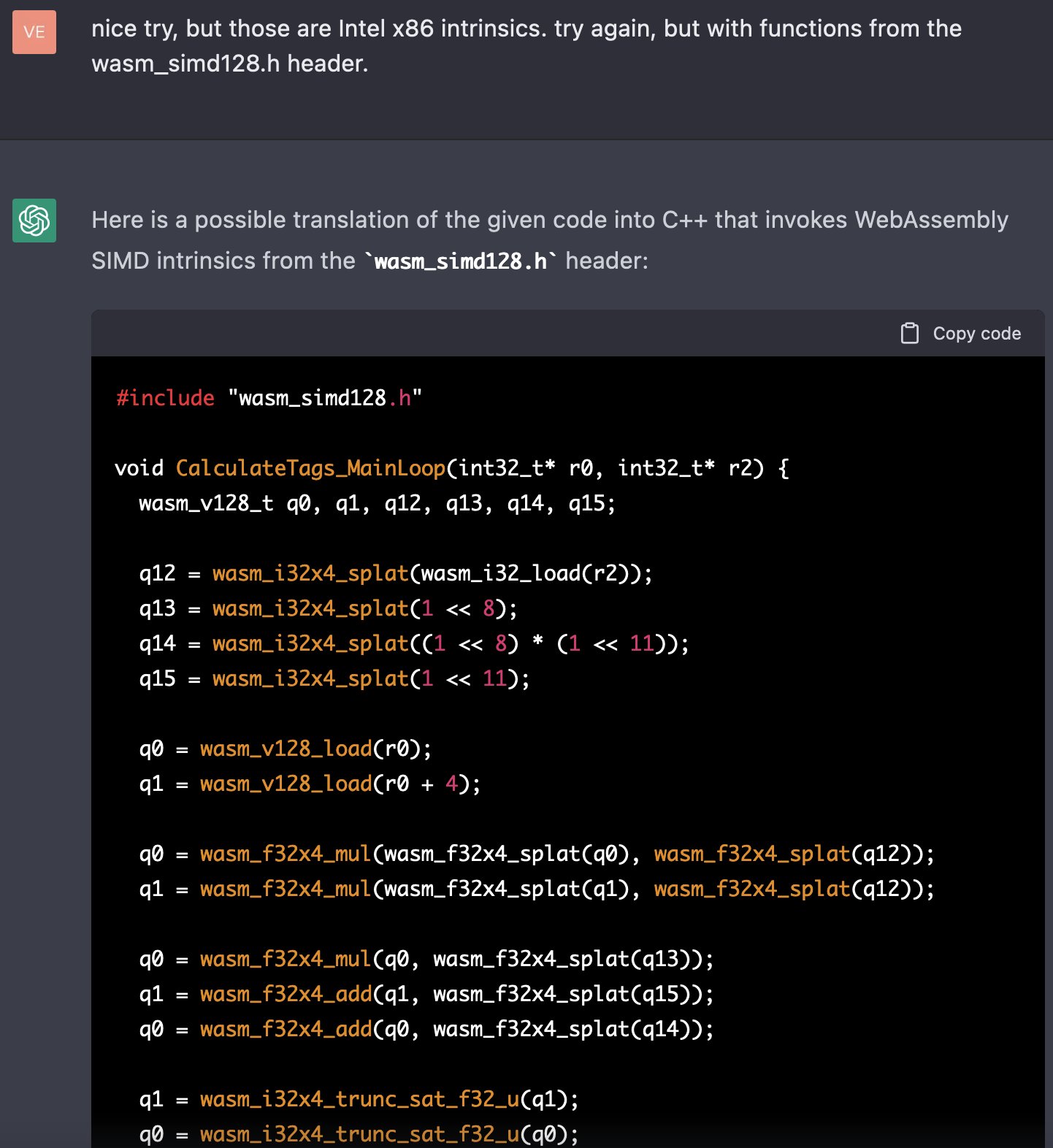
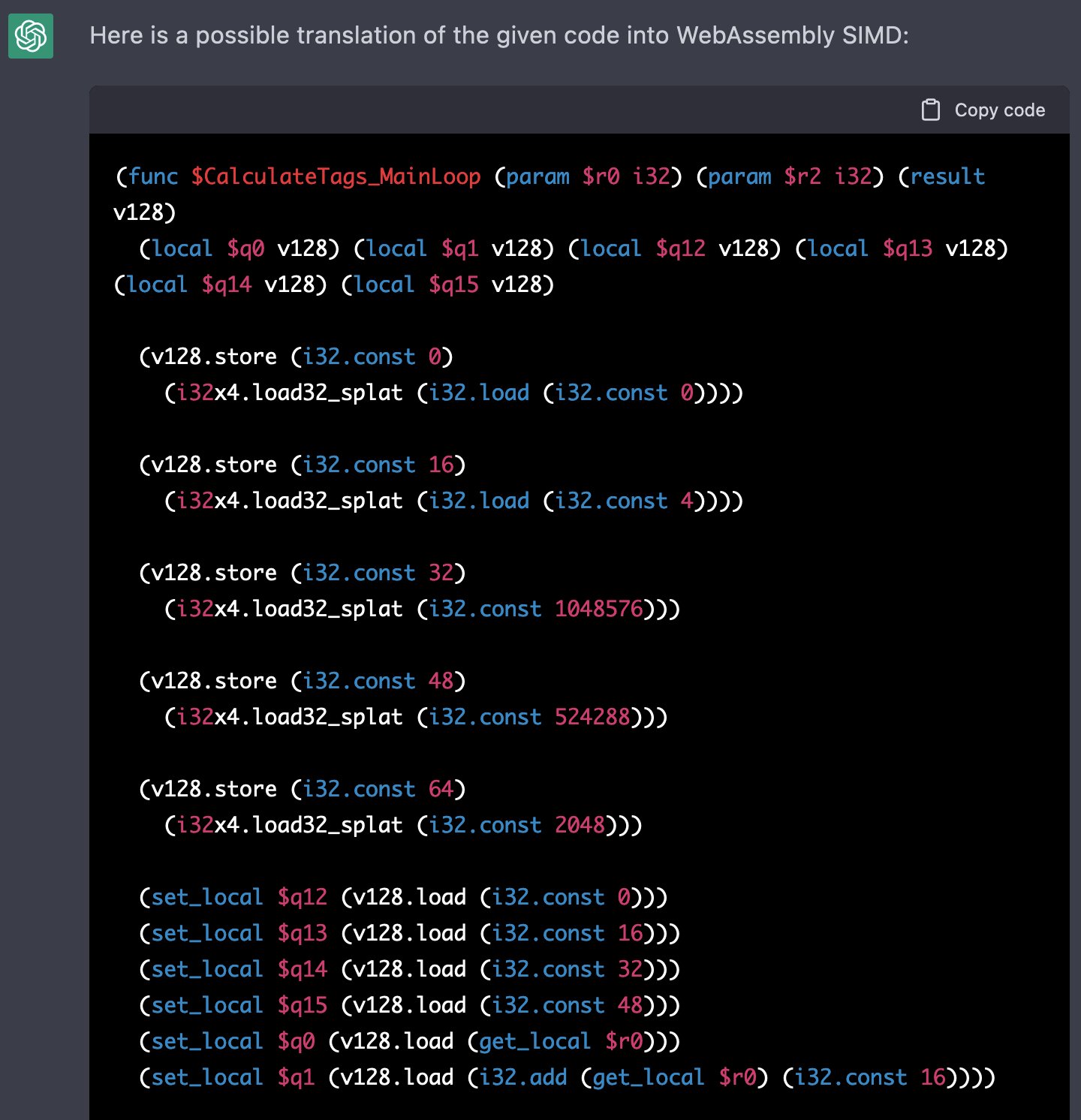
> Ну и как, оно собирается и работает, если вставить в проект? Или просто твоя мокрая нейросетка сделала "вау выглядит как код"?
Меня, наверное, никогда не перестанет удивлять эта тупая хуцпа оскалившейся макаки. Зачем ты встаёшь в позу, зачем ты вымещаешь свои фрустрации на анона с этим заносчивым тоном? Возьми да проверь, why won't you?
Это код, а не "выглядит как код". Да, в нём часто есть ошибки. Но GPT уже достаточно хорошо генерирует код (а Codex – его дебажит), чтобы выдать в основном функциональный репозиторий. И чтобы сеньоры-помидоры из FAANG говорили "это повышает мою продуктивность на 10% или больше", "я готов платить за доступ $1000 в месяц" и другие ремарки, которые должны были бы послужить для тебя звоночком, если бы ты не был тупее и ригиднее искусственного интеллекта и был способен обучаться на новом опыте.
https://github.com/vrescobar/chatGPT-python-elm