Роботы
Трансформеров, видимо, хватит и для управления роботами. Новая модель гугла хорошо понимает естественный язык и новые среды, знает 700 разных задач. Для управляемого так робота не составит проблемы, например, в новой кухне протереть стол по команде "возьми тряпку и приберись". (как я уже сообщал в >>/1222/, whisper V2 имеет высокий человеческий уровень распознавания речи, так что можно всё делать локально в реальном времени).
https://robotics-transformer.github.io
https://allenai.org/project/phone2proc/home от Института Аллена – дешёвое и эффективное дообучение модели среды на основе обычной записи с айфона. Устойчиво к дальнейшим изменениям вроде перестановок мебели или прихода/ухода людей.
https://video-dex.github.io – Карнеги-Меллон. Обучение поведения роботов на массиве человеческих видеозаписей.
Фундаментальное
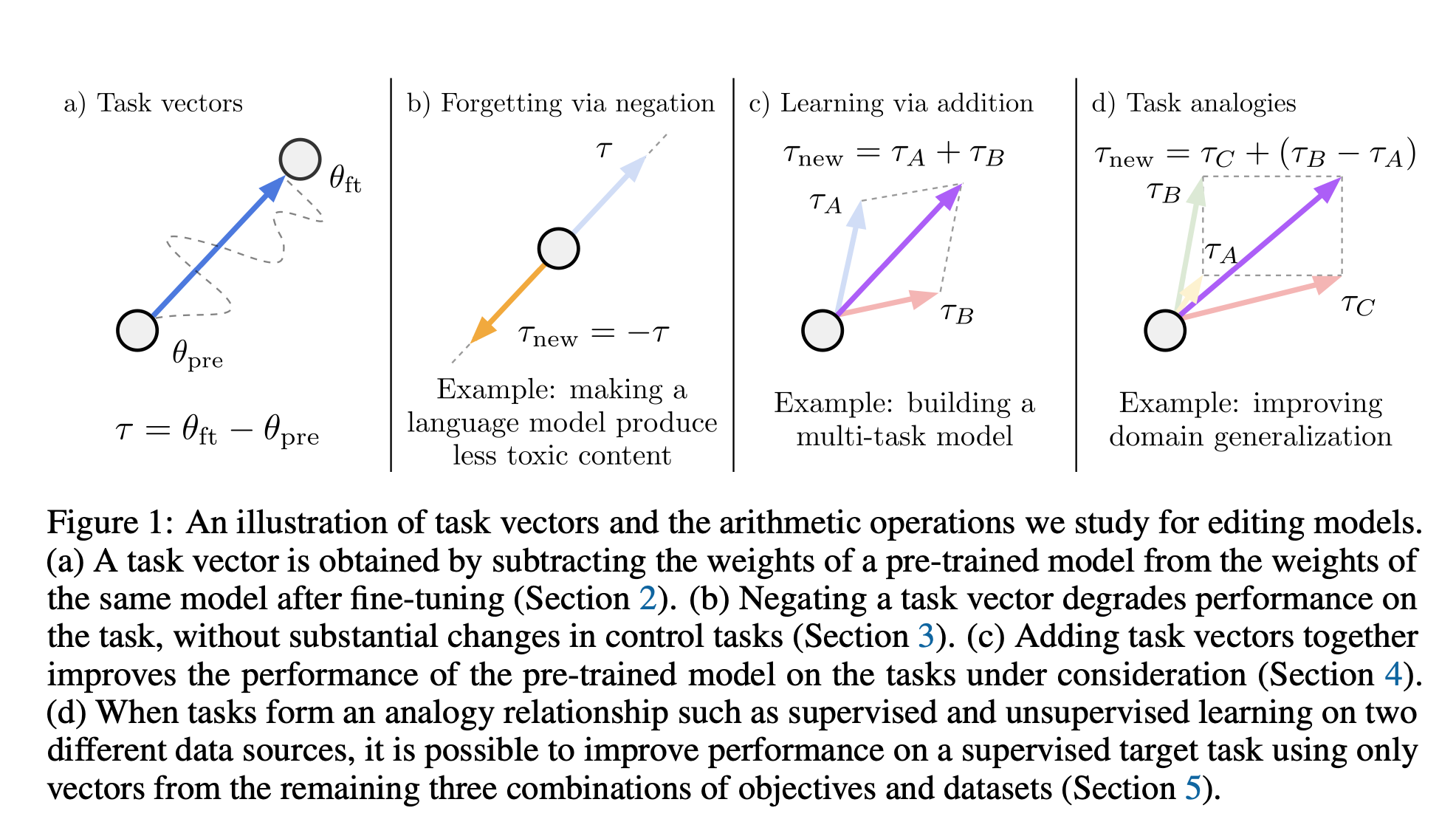
https://arxiv.org/abs/2212.04089 – арифметика файнтюнинга. Можно просто дообучить модель на N задачах, представить дообученные модели как векторы, добавить их к базовой модели и её успешность в выполнении каждой из этих задач повысится почти до того уровня, что может соответствующая специализированная модель. Типичный аниме-троп, ничего нового.
https://arxiv.org/abs/2212.04458
Универсальное обучение в контексте посредством мета-обучающихся трансформеров, Гугл. Вероятно будет очень важной вехой, во всяком случае Сол-Дикштейн на это опять надеется.
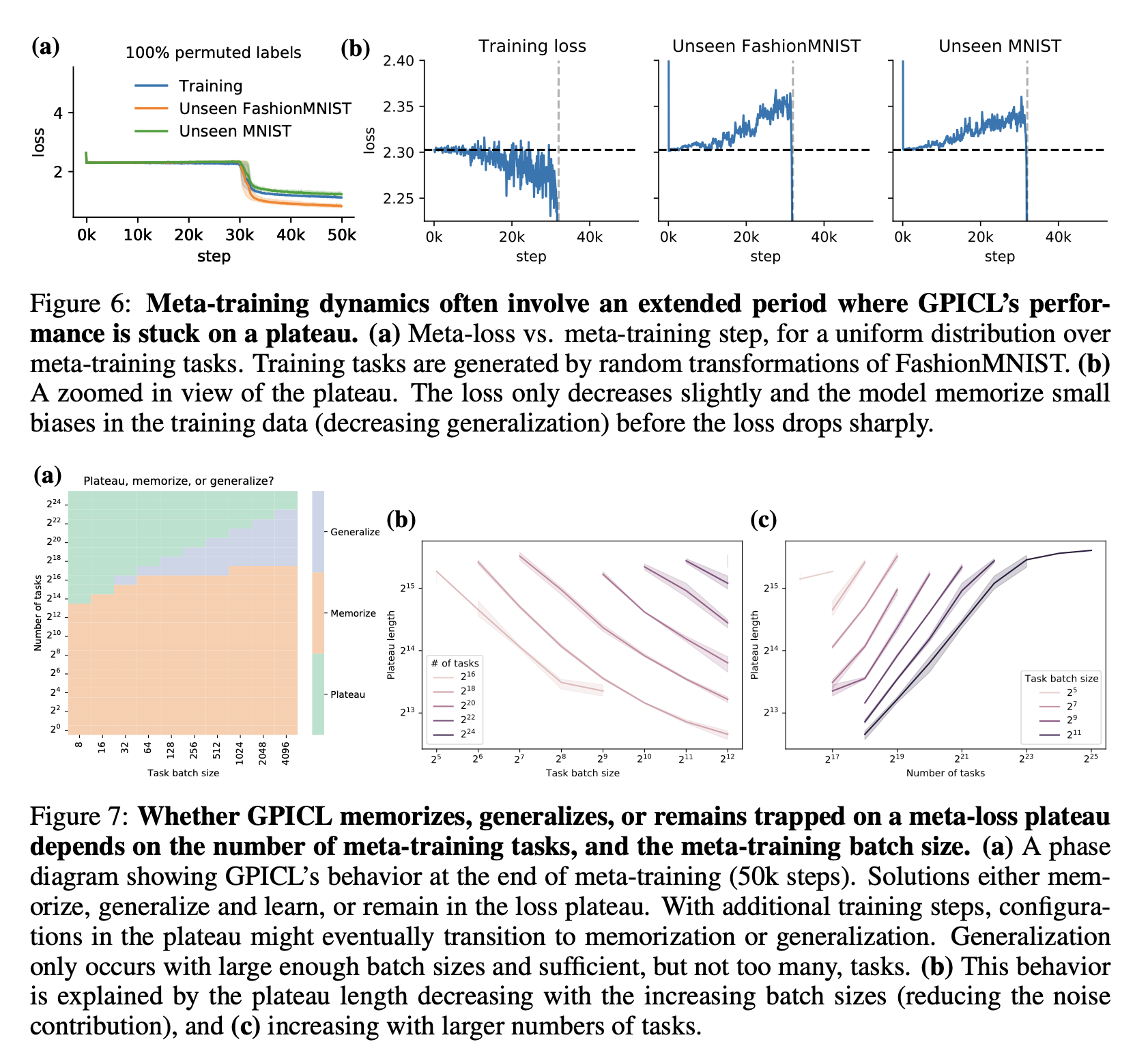
"Современное машинное обучение требует, чтобы разработчики систем определяли аспекты конвейера обучения, такие как лосс, архитектуры и оптимизаторы… Одна из особенно амбициозных целей мета-обучения - обучение алгоритмов контекстного обучения общего назначения с нуля, используя только модели "черного ящика" с минимальным индуктивным биасом. В этой статье мы показываем, что трансформеры и другие модели "черного ящика" могут быть мета-обучены для работы в качестве внутриконтекстно обучающихся моделей общего назначения. Мы характеризуем фазовые переходы между алгоритмами, которые обобщают, алгоритмами, которые запоминают, и алгоритмами, которые вообще не поддаются мета-обучению, вызванные изменениями в размере модели, количестве задач и мета-оптимизации. "
https://www.cs.toronto.edu/~hinton/FFA13.pdf – Forward-Forward Algorithm, Хинтон, гугл.
Если это выгорит, то мы сможем избавиться от backprop, получить почти бесплатное масштабирование сетей, лёгкую параллелизацию, быстрое обучение, категорически упростятся архитектуры и вообще всё, исчезнет нужда в дифференциируемости модели. Это будет прорыв уровня… самого по себе глубокого обучения.
Images
https://github.com/zsyOAOA/DifFace – вероятно лучший опенсорсный восстановитель фотографий.
https://huggingface.co/spaces/ysharma/Low-rank-Adaptation – эффективный, более быстрый, точный файнтюн stable diffusion, сжимающий изменения в 6 мегабайт вместо 2+ Гб.
https://github.com/weixi-feng/Structured-Diffusion-Guidance – простейший трюк добавляет stable diffusion понимание композиции сцены.
https://arxiv.org/abs/2212.05221 – очередная retrieval-augmented модель с внешней мультимодальной памятью.
https://github.com/frozoul/4K-NeRF – нейронные поля излучения в 4К, по сути самый простой путь создания 3Д-репрезентаций реальных объектов из набора статических изображений.
По видео, 3Д и проч. уже скучно.