pass_rate_graph jpg
(131.42 KB, 1000x871)
>>/3835/
Даже конкретнее:
https://arxiv.org/abs/2310.20216
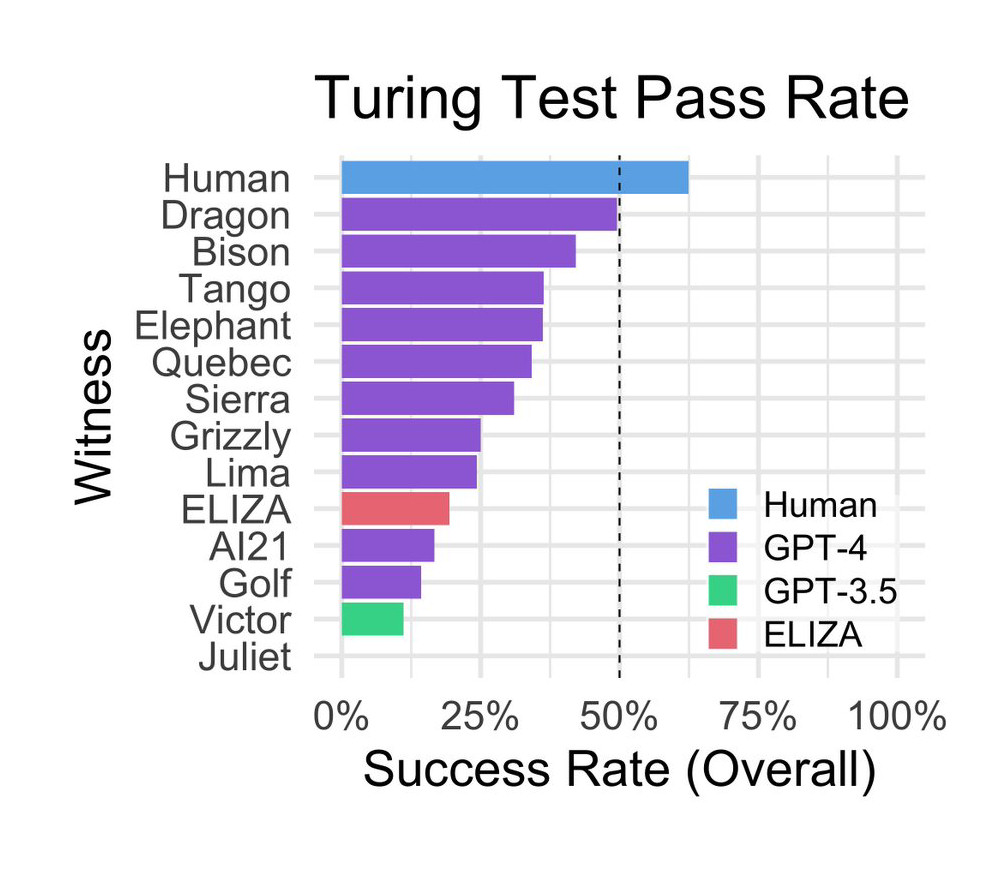
> The best-performing GPT-4 prompt passed in 41% of games, outperforming baselines set by ELIZA (27%) and GPT-3.5 (14%), but falling short of chance and the baseline set by human participants (63%). Participants’ decisions were based mainly on linguistic style (35%) and socio-emotional traits (27%), supporting the idea that intel- ligence is not sufficient to pass the Turing Test.
First, ELIZA’s responses tend to be conservative. While this generally leads to the impression of an uncooperative interlocutor, it prevents the system from providing explicit cues such as incorrect information or obscure knowledge. Second, ELIZA does not exhibit the kind of cues that interrogators have come to associate with assistant LLMs, such as being helpful, friendly, and verbose. Finally, some interrogators reported thinking that ELIZA was “too bad” to be a current AI model, and therefore was more likely to be a human intentionally being uncooperative.
Хорошо не уметь читать, да, кальсон? Легче не замечать, как вконец запизделся.