endchan_markup (1) png
(177.17 KB, 1920x804)
>>/660/
Эти картинки (с сервалом в свитере) анон с Новеря же генерирует. У него как раз локальный дифужон с этим всем, да.
Получается, можно не рассчитывать получить что-то приемлемое из этой демки https://huggingface.co/spaces/runwayml/stable-diffusion-v1-5?
Даже на "a man picking apricots- from a tree" оно выдает хорошую фотореалистичность, но с аниме-стилем без "колдовства" сразу начинается derp.
> Вот нарисованный краб с отрицательной и положительной [photography] (угадай где какой промпт).
Думаю 649f6971 с положительной фотографией, 54e6981eс отрицательной.
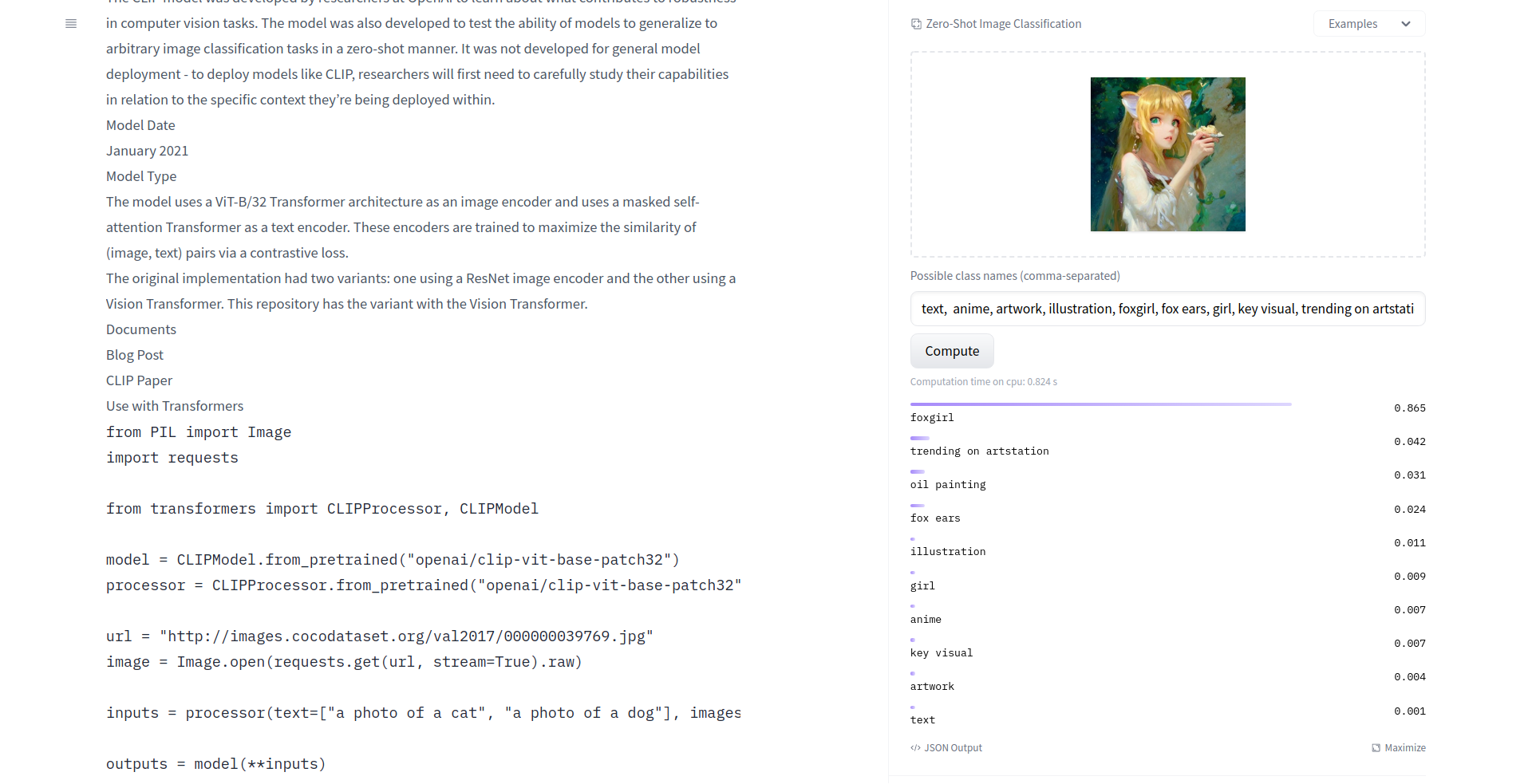
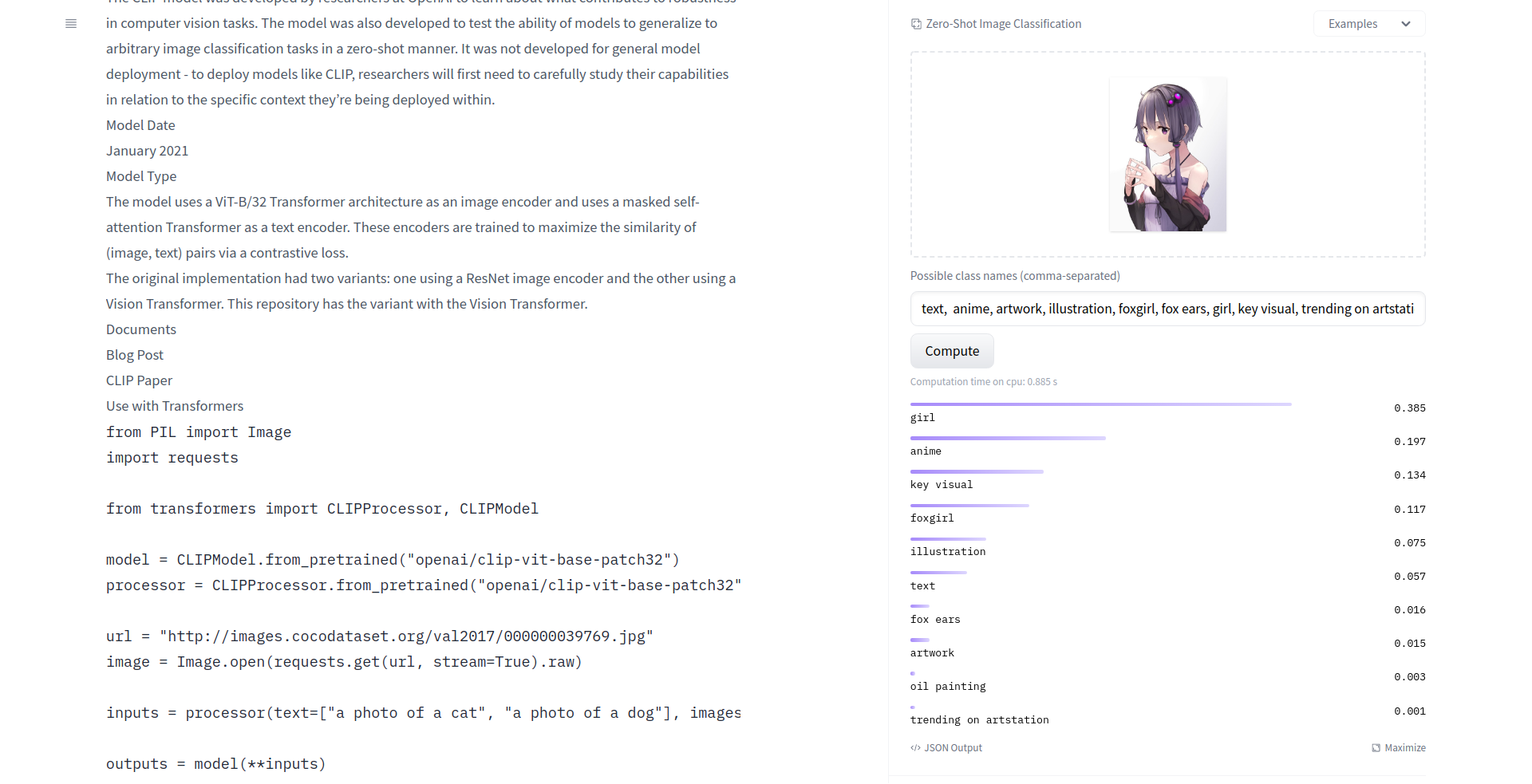
> Но ты можешь вручную проверять CLIPом пакет векторов типичных кейвордов.
Вот так?
Эта хотелка родилась у меня от того, что я не знаю вообще какие ему нужны для качественного результата.
Но я так и не понял, что мешает инверснуть процесс - не картинка после магических слов, а слова по картинке. Почему так нельзя сделать с уже имеющимися моделями?