Actions
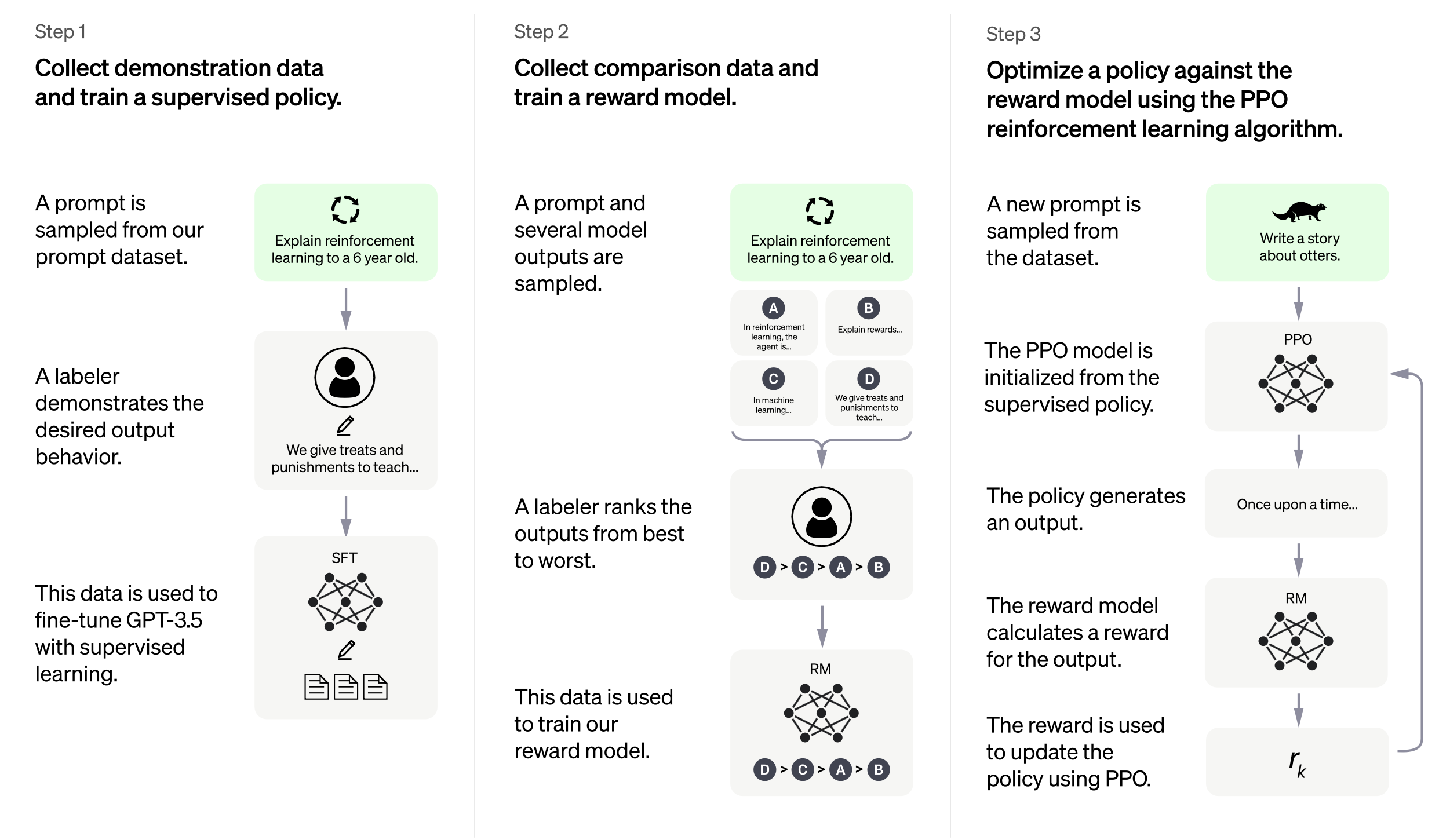
(545.52 KB, 2502x1450)

(83.58 KB, 843x1005)
>>/952/ Для начала, эта проблема – неудачное начало ответа заставляет модель продолжать блажить – обходится уже сейчас банальными механизмами вроде best of N, то есть генерацией нескольких линий ответов с разными случайными сидами и сравнению их по качеству (даже банальной perplexity по оценке самой модели). Учитывая скорость генерации ChatGPT, при best of 20 она всё ещё будет в разы быстрее человека. Есть более изощрённые механики из этого класса, например self-consistency https://arxiv.org/abs/2203.11171 Всё это очень похоже на человеческую проблему трейдоффа глубокого и быстрого мышления, система 2 vs. система 1. Но дело даже не в этом. > Каким образом ты полагаешь GPT - мозг-в-банке - сможет это синтезировать? Ещё по RLHF погоняют (пикрелейтед) и у неё появится интуитивное понимание правильных ответов на кодерские вопросы. Этот "публичный бета-тест" для того и используется. Думаешь, вы такие умные, что тиражируете в сети примеры ошибок? Всё это пойдёт в дело как начало вектора от нежелательных к желательным ответам, и она не просто запомнит частные случаи (ей некуда их запоминать), а обобщит принцип, как уже обобщила очень многое, как может обобщить принцип микроагрессии на воображаемый диалог между макаронами и удоном или стиль речи гангстера на мануал по computer science. В достаточно большой и плотной модели углубление понимания каждого домена приводит к росту понимания всех связанных доменов. Тебя не смущает, что ты приводишь аналогию с глупым человеком и материалами, написанными глупыми людьми? Ровно такого сорта контент можно получить от индуса на странице поддержки. Два года назад за подобные аналогии ты бы предложил пить таблетки, ведь было "очевидно", что модель просто перебирает слова, теряя когерентность даже между предложениями. Тебя не смущает, что ошибок и откровенного бреда стало намного меньше? Почему ты так привязан к тому, чтобы выискивать failure modes, а не оценивать количественно и качественно разницу между поколениями ИИ и изучать, как эта разница была достигнута? А я скажу почему. Потому что вот это – > Вот человек может *заморочиться* и *реально* выяснить – неправда. Люди ограниченны. Дурачок-индус *не может* просто подумать подольше и найти верное решение без копипастинга из чужой работы, он упирается в свой потолок. Ты тоже не можешь просто напрячься, отвлечься от защиты своего статуса и проанализировать вопрос от первых принципов, вместо того занимаясь *бесполезным бормотанием* про мозг в банке (интересно, какие ещё органы, по-твоему, нужны для понимания линукс-драйверов). Ты на том же уровне когнитивной сложности, что и ChatGPT, вы похожим образом фейлите на сложных задачах, вам обоим нельзя доверять. Разница в том, что у тебя меньше эрудиции и ты хуже признаёшь ошибки, но зато у тебя есть гугл. У полной версии будет доступ в интернет, собственно он уже есть, просто его отключили. Вот пример того, как это будет работать: https://twitter.com/altryne/status/1598848397855031296 – нейросеть может читать новую документацию и выдавать улучшенные ответы. Она уже может писать тесты, уже может дебажить код, и нет никакой проблемы настроить её так, чтобы в случае фейла тестов она не ждала человеческого пинка, а сама перебирала другие варианты и рылась в примерах и документации, пока не найдёт хорошего решения. И давай без "вот покажут, тогда и приходите" – по отдельности всё это было показано, хотя бы и здесь https://mobile.twitter.com/nearcyan/status/1587207677402390534 И разумеется она сможет самообучаться на основе итераций тестов. > массив публичных текстов - это в общем-то такое себе приближение к реальности. Это и придает некую идиотскость мозгу в банке А что придаёт "идиотскость" индусу из саппорта? Это не очень интересная тема. Всё, что есть интересного в нашей культуре, либо прямо выражено в тексте, либо выражено в нём имплицитно (твои умолчания оставляют искажения, как чёрная дыра в потоке излучения), либо не имеет коммерческого смысла.